Power BI Implementation Models for Enterprises – Part 2 (Cloud-Native Clients)


{kind=link}
This is article two in a series describing how I implement Power BI systems in enterprises. In my first article, I described how I and my company categorize the clients that we work for to one of the following categories:
- Cloud-native
- Cloud-friendly
- Cloud-conservative
- Cloud-unfriendly
In this article, I’ll describe how we work with the first group: the cloud-native clients.

{kind=link}
Cloud-Native Clients
These are my favorite clients.
They are very comfortable with using cloud-based Software as a Service (SaaS) applications. They accept the idea that their data will live in cloud-based storage. In most cases, they are already using cloud-based SaaS applications. These will be the primary source systems for the analytic work.
Starting Point
When I start working with them, their architecture often looks like this:
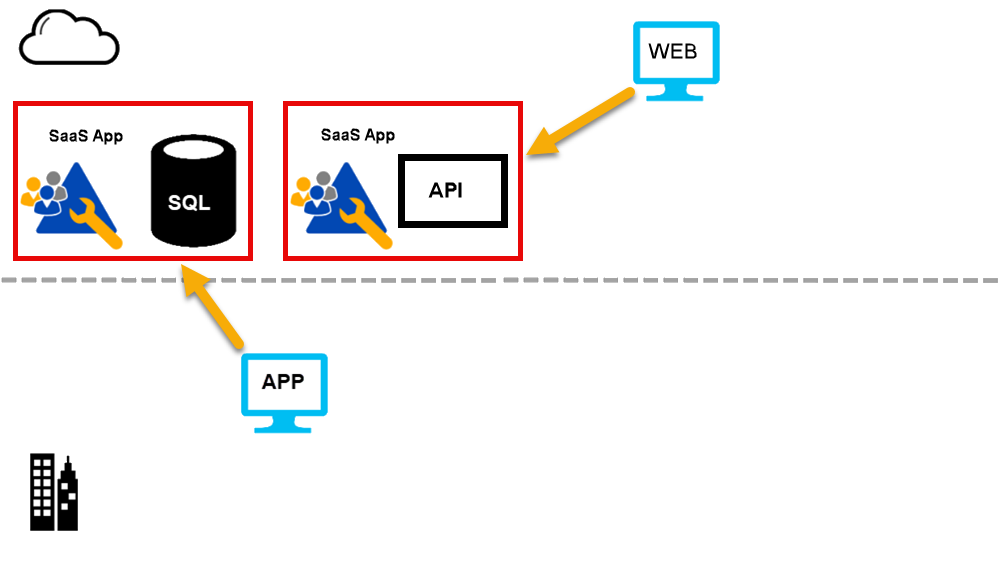
{kind=link}
Clients often have several Software as a Service (SaaS) applications that they use. Examples are:
- Sales apps
- Customer relationship management (CRM) apps
- Human resources (HR) and payroll apps
- Helpdesk apps
I see the clients connecting to these applications in two ways:
- by using a website provided by the app vendor
- by using a native app that they have deployed on a local machine.
Native apps are installed on computers, phones, and/or tablets. We extract data from the apps by:
- calling an application programming interface (API). (Most of these are REST based.)
- reading files exported on a schedule to a cloud-based storage account.
- or (less often), connecting to the vendor database.
To be useful, the SaaS application must provide a way to allow external systems to extract data that is held by the application. If they don't, I tell the customer they should change to using another application. It is so important today to use applications that aren't information silos.
First Step: Stem Any Potential Identity Mess
In far too many cases, the clients already have the start of an identity mess. They'll have different usernames and passwords for each of the SaaS applications. There is no need for this.
Many of the clients will already be using one or more Microsoft 365 products. They might be using Microsoft Word or Microsoft Excel. If they are, this is good news as they will already have a Microsoft Entra ID (formerly Azure ID) tenant in place. The exception is where they have used personal licenses for these products. If they have personal licenses, I encourage them to move to organizational licenses.
As they are going to be using Power BI, they will need a Microsoft Entra ID tenant. If they already have one from Microsoft 365 or other product/service, great. If not, I create one for them.
One beauty of a tool like Microsoft Entra ID is that it can authenticate users for SaaS applications. It is not limited to Microsoft applications. So, if a user wants to use ZenDesk for a helpdesk, they should use a Microsoft Entra-based identity. Same for DropBox, and so on. Most current SaaS applications support Microsoft Entra ID.
I need to stop the spread of cloud identities immediately; users cannot safely manage a large number of separate identities. I mentioned that SaaS applications that can't export data aren't useful. It's the same for those that don't support Microsoft Entra ID for identity. I encourage clients to move to applications that support Microsoft Entra ID. There are plenty to choose from.
Once I’ve dealt with identity, I hope to have this architecture:
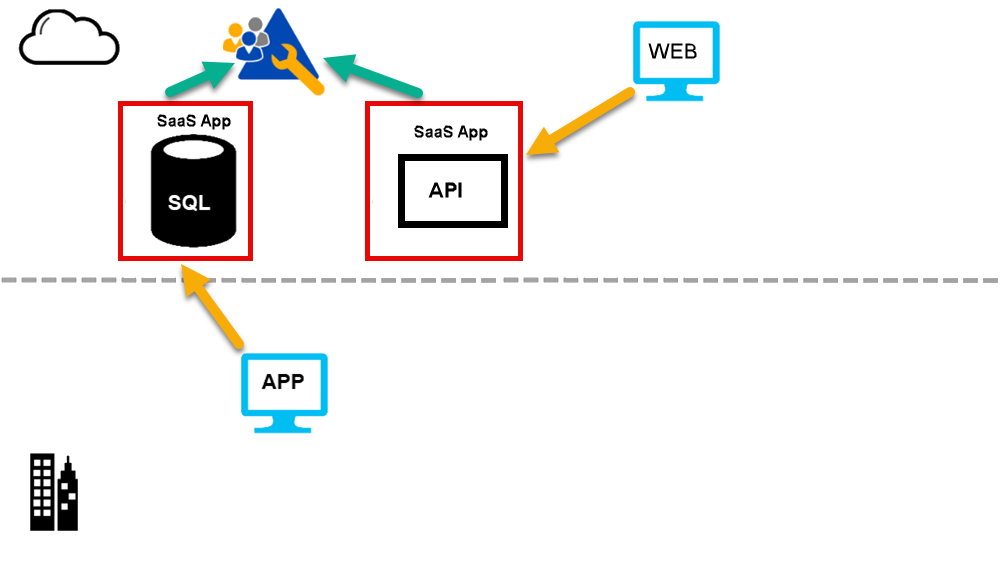
{kind=link}
By this stage, as many of the SaaS applications as possible are using Microsoft Entra ID as their identity provider.
Second Step: Data Warehouse
For cloud-native clients, I will typically implement the following type of solution:
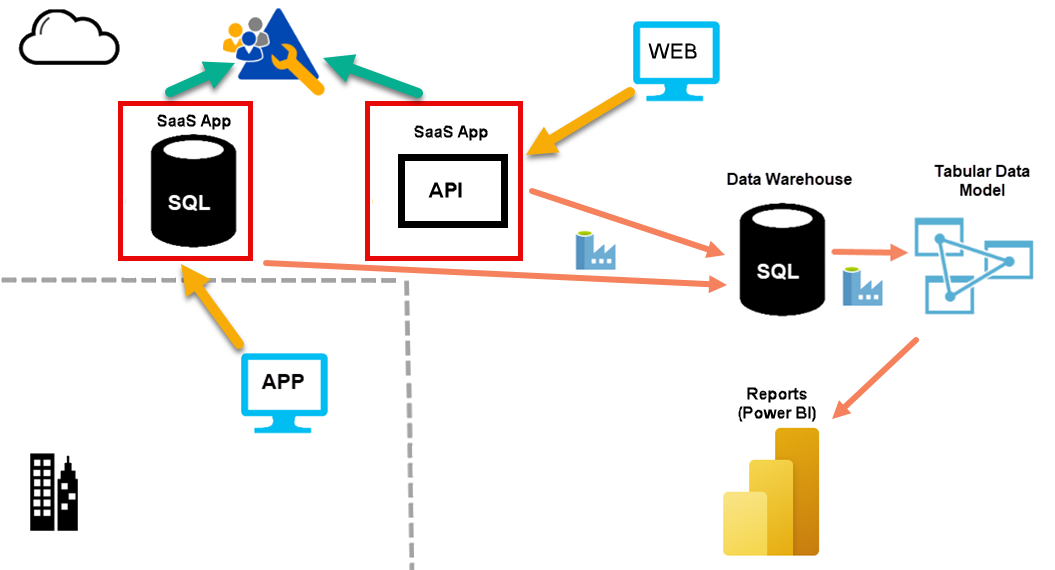
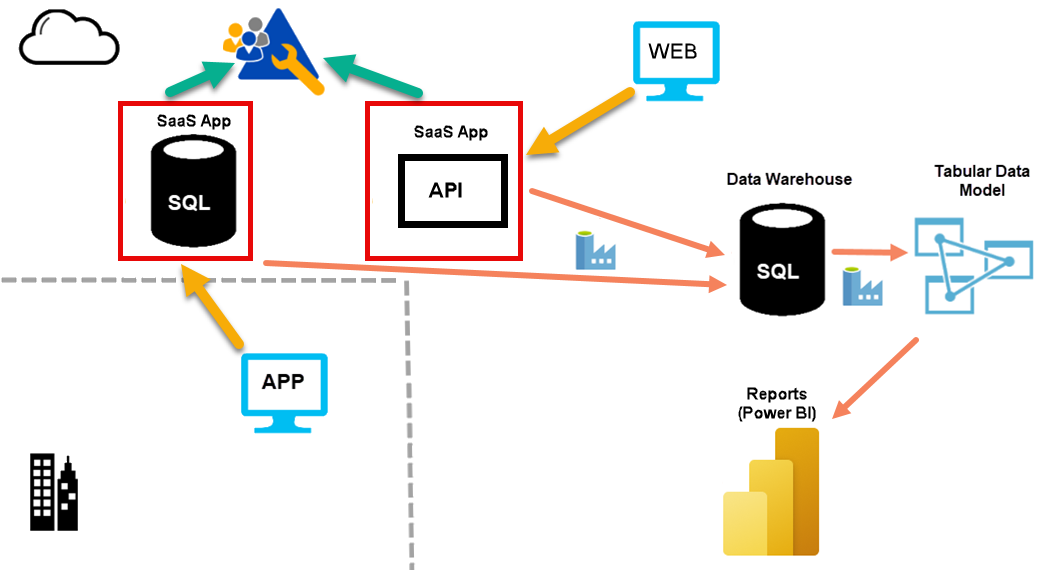{kind=link}
I create a data warehouse in Azure. Mostly I use Azure SQL Database. While I could potentially use Azure SQL Managed Instance or Azure Synapse Analytics, the costs associated with this are rarely justified for this part of our projects. At the time of writing, I consider a Microsoft Fabric warehouse to not be sufficiently mature enough to use for this purpose. Azure SQL Database is a great fit for this, and it is both scalable and cost effective.
Data Warehouse Structure and Purpose
For most clients, I use a single data warehouse. In that warehouse, I will:
- reshape the data.
- cleanse the data.
- version the source data.
- align the data from many source systems if required.
I need to ensure that the data is ready to load into a tabular model (for Power BI or Excel or SSRS, or other uses). I don’t want to apply complex transformations in the loading phase for the tabular model.
The data warehouse contains areas that represent stages of processing. In data lake systems, I see discussion on medallion architectures. This is similar. I use schemas to separate these areas.
I'll discuss more about how I structure the data warehouse in a later article.
Tabular Data Model
For a tabular data model, I use either Azure Analysis Services or Power BI Premium.
I'm a fan of Azure Analysis Services. I find it has an appropriate blend of capability and cost. The exception to this is if the client already has, or can justify the cost of, Power BI Premium licensing. For us, that means clients who will have more than about 300 users of the final Power BI reports. Power BI Premium licensing is not currently cost effective for smaller clients.
In the future, semantic data models in Microsoft Fabric might provide the tabular data model that I need. At present, most of these clients are not using Microsoft Fabric yet.
Azure Analysis Services (AAS) is also a great point for connecting other tools. This includes Microsoft Excel and SQL Server Reporting Services (SSRS). Some clients are still using SSRS. Those connections can use the same row level security.
Note: I do not recommend using AAS as the source of data for further transformation or ETL work. For example, some clients use tools like Tableau. I supply the data they need from the dimensional data warehouse, not from AAS.
Scheduled Data Movement
I use Azure Data Factory (ADF) to manage the movement of data from source systems into the data warehouse. I also use ADF to schedule this data movement.
For most clients, I need to schedule the processing of the tabular data model. Scheduling refreshes from within Power BI is not flexible enough. I use ADF to schedule this process.
Note: I do not use DataFlows in ADF to perform transformation. Most clients think that ADF is a low-cost service. Clients with cost concerns are those using DataFlows and/or the SSIS Integration Runtime. I avoid both.
The Azure-based alternatives to ADF are:
- Azure Synapse pipelines
- Microsoft Fabric data pipelines
ADF is currently more capable and flexible than either of these. This might change in the future but currently, I see ADF as a superset of Azure Synapse pipelines, and Azure Synapse pipelines as a superset of Microsoft Fabric data pipelines.
Azure SQL Database
I prefer Azure SQL Database. It is the type of database that I try to use every time. You want to hand over day-to-day management of databases like this to Microsoft. You want a T-SQL end point to talk to, and you want to manage the database declaratively, not procedurally. You want to say how big a database should be, how fast it should be, and which region it is in. You also want to say if you need a replica, which region that's in, and if it is readable.
You do not want to be managing the low-level activities of how all that works. And you do not want to need to retain and train staff who know how to do those things.
I look at our own administrative databases. Years ago, I had them running on virtual machines. I had ongoing work to keep them running and secure. From the point that I migrated them to Azure SQL Database, I have almost never thought about them again. They just work. That is what you want for your projects too.
Power BI
Power BI is now the most popular visualization tool for analytics. Most clients that I work with are happy to use it but the architecture that we put in place would allow for the use of other analytic tools. In a later article, I will discuss how we implement visualization using Power BI.
Azure DevOps
It is important to manage development projects, and projects for implementing Power BI in enterprises are no different. If a client already has a tool for source control, versioning, and project management, I'm happy to work with whatever tool they prefer. When I am choosing a tool, I currently prefer to work with Azure DevOps. It provides the capabilities that I need at a very low cost, and integrates well with Microsoft Entra ID.
Summary
For projects targeting cloud-native clients, I typically use these tools from the Microsoft stack:
- Microsoft Entra ID (EID) for identity management
- Azure SQL Database (ASD) for creating a data warehouse
- Azure Analysis Services (AAD) or Power BI Premium (PBIP) for the tabular data model
- Azure Data Factory (ADF) for moving data and for orchestrating data movement and processing
- Power BI (PBI) for reporting and visualization
- Azure DevOps (AzDO) for project management, source code control and versioning
And optionally:
- Microsoft Excel for ad-hoc queries over the analytic data model
- SQL Server Reporting Services (SSRS) or Power BI (PBI) for paginated reports
In the next article, I'll describe how I change this for cloud-friendly clients.

Greg Low
Greg is a member of the Microsoft Regional Director (RD) program. Microsoft describes RDs as “150 of the world's top technology visionaries chosen specifically for their proven cross-platform expertise, community leadership, and commitment to business results.”
He is the founder and principal consultant at SQL Down Under, a boutique data-related consultancy operating from Australia. Greg is a long-term data platform MVP and a well-known data community leader and public speaker at conferences world-wide.
Greg has a pragmatic attitude to business transformation and to solving issues for business of all sizes.